「学习笔记」数据结构与算法 -- 排序算法
排序算法可以分为内部排序和外部排序,内部排序是数据记录在内存中进行排序,而外部排序是因排序的数据很大,一次不能容纳全部的排序记录,在排序过程中需要访问外存。常见的内部排序算法有:插入排序、希尔排序、选择排序、冒泡排序、归并排序、快速排序、堆排序、基数排序等。
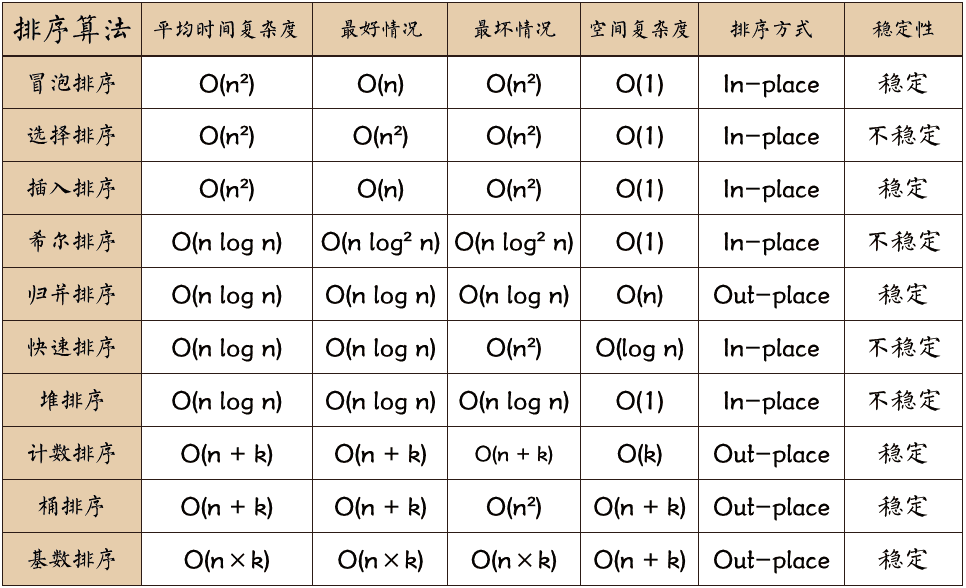
用一张图概括:
名词解释:
n:数据规模k:“桶"的个数In-place:占用常数内存,不占用额外内存Out-place:占用额外内存稳定性:排序后 2 个相等键值的顺序和排序之前它们的顺序相同
| 内部排序 | 描述 |
|---|---|
| 冒泡排序 | (无序区,有序区) 从无序区通过交换找出最大元素放到有序区最前端。 |
| 选择排序 | (无序区,有序区) 从无序区选择一个最小的元素放到有序区的末尾。比较多,交换少 |
| 插入排序 | (无序区,有序区) 把无序区的第一个元素插入到有序区合适的位置。比较少,交换多 |
| 希尔排序 | 通过比较相距一定间隔的元素来进行(每一定间隔取一个元素组成子序列),各趟比较所用的距离随着算法的进行而减小,直到只比较相邻元素的最后一趟排序为止。 |
| 归并排序 | 把数组从中间分成前后两部分,分别排序,再将排好序的两部分合并。 |
| 快速排序 | (小数,基准,大数) 随机一个元素作为基准数,将小于基准的元素放在基准之前,大于基准的放在基准之后,再分别对小数区与大数区进行排序。 |
| 堆排序 | (大顶堆,有序区) 取出堆顶元素放在有序区,再恢复堆。 |
| 计数排序 | 统计小于等于该元素值的元素个数i,于是该元素就放在目标数组的索引i位(i>=0)。 |
| 桶排序 | 将值为i的元素放在i号桶,最后依次把桶里元素倒出来。 |
| 基数排序 | 一种多关键字的排序算法,可用桶排序实现。 |
1. 冒泡排序(Bubble Sort)
冒泡排序(Bubble Sort)是一种简单直观的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。